

はじめに
東京科学大学の福田です。現在チームMA-KINGにて、ロボット競技会CoREにおける4足歩行ロボット開発を行っています。
本ブログでは、弊チームにおける開発記録と改良の過程について紹介します。 これまでMA-KINGのXアカウントにて投稿してきた動画と絡めながら、何がどう悪かったのか、私自身の考えを実際のログなどを通じて説明していきます。Xに投稿していない動画なども掲載しているのでぜひご覧ください。
強化学習に関するノウハウに相当するものがなかなか情報として入手しにくいかと思いますので、オープンソースハードウェアであるMEVIUSを使った開発経験を共有し、今後開発する方の一助になれば幸いです。
開発記録
Isaac Labを使った学習環境の構築
学習環境の構築は、こちらのLocomotion Exampleからスタート。
Available Environments ? Isaac Lab Documentation
モデルはこちらで公開されているので、Isaac SimのURDF Importerを使用してMEVIUSのusdファイルを作成し、ハードウェアパラメータを適宜参照しながら各種設定を行いました。
学習設定などはlegged_gymでの学習用のコードを公開してくださっているので、そちらを参考に、Isaac Labに読み替えて実装しました。
IsaacLabでMEVIUS制御器の学習環境が構築できました! これから競技に更に特化した制御器を開発していきます💪#CoREjp #CoREjp_MAKING pic.twitter.com/yVLghRYRUL
? MA-KING (@ma_king_core) December 11, 2024
作成したIsaacLabのコードはこちらで公開しています。
また、使用方法もこちらで解説しておりますのでぜひご覧ください。
Isaac Labでの強化学習 ? 4足歩行ロボットMEVIUS製作 Part.4
公開モデルの検証
Isaac Labでの学習環境構築と同時並行でMEVIUSの組み立てと検証を手分けしておこなっていました。このおかげでハード・ソフトの動作チェックは完了し、制御器(ポリシー)を変えればいろいろ試せる環境になりました。
ソースコードが公開されているので、ここをスタート地点とすることができました。realで歩くことができるポリシーが公開されているのは、我々が作成した学習結果を適用する前に、他の問題の可能性を潰すことができるため、非常に助かりました。オープンソースの強みを感じます。
また、公開されているポリシーを試すことで、我々が独自で開発する必要性についても認識することができました。
歩きました!!!!!!!!#CoREjp#CoREjp_MAKING pic.twitter.com/8D38maM9US
? MA-KING (@ma_king_core) January 1, 2025
ジョイントの整合性
さて、学習もできたし、歩くようにもなったし、作ったポリシーを一旦試しに入れてみよー!といって試したのがこちらの動画一個目です。
結果、歩行モードに入った途端、Jointが大きく暴れました。これは、NNの出力と実機制御側のJointの順序の整合性をとっていなかったためです。当然保証しておくべき事案ですね(笑)
sim to real を試す前にsim to simを試すのが重要ということを経験でもって再認識しました。
(開発期間中にIsaac LabでJoint順序指定に関する実装がバグのない形で追加されました。これは新しいフレームワーク特有の面白さですね。)
本日の4脚歩行の練習の様子です#CoREjp#CoREjp_MAKING pic.twitter.com/fCo3ZJ7bh4
? MA-KING (@ma_king_core) January 13, 2025
PDゲイン調整 & Networkサイズ & actionの滑らかさ
NNの出力の順序とJointの順序の整合性を合わせて適用した結果がこちらになります。
Sim2Real#CoREjp#CoREjp_MAKING pic.twitter.com/Jxz4QtwJYZ
? MA-KING (@ma_king_core) January 18, 2025
振動して大暴れです。
ここから原因究明に入ります。
以下は判断材料や推測を列挙したものになります。問題があると判断した要素、問題ないと判断した要素の両方を記載しています。
- sim (mujoco)上で歩行させたときのある足の3関節の目標角と現在角のログがこちらになります。このログを見ると、目標角度が激しく変化しすぎていることがわかります。これは強化学習ベースにおける平滑化報酬が小さすぎることが原因だと考えられます。
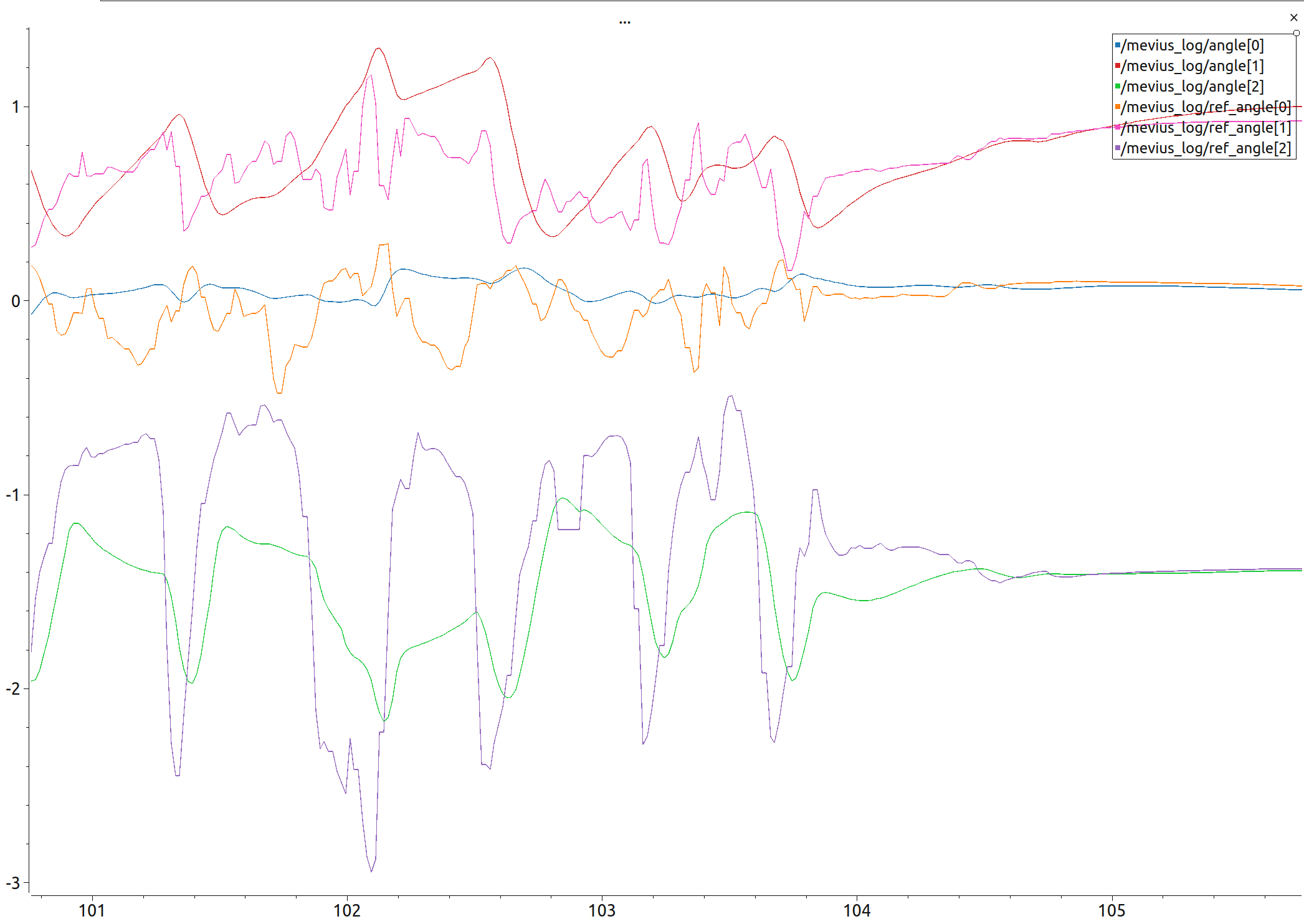
- 実機の各軸の観測速度・角速度、機体の観測並進速度・角速度のデータを確認し、観測値のノイズ範囲が、十分学習時のノイズ設定の範囲を超えていないことも確認しているため、学習時の観測情報のノイズが足りない、ということはないと考えました。
- ポリシーの出力は各軸の目標位置で、最終的な出力トルクはこの目標位置に対する下位のPD制御によって決定されています。このPDゲインは小さい方が外乱に対して適応的な動作が可能だと考え、公開されているPDゲインから下げていました。これが低すぎたことが問題でした。またこのゲインは、待機姿勢から初期姿勢に立ち上がることもままならないゲインだったというのもあり、歩行時に必要なトルクを十分に出力できず、安定しないということも考えられます。加えて、低すぎるPDゲインは、アクション(ポリシーの出力)に対する各軸の応答性にも影響を及ぼし、振動を発生させる要因にもなりうるとも考えました。そのため、ある程度のPDゲインの高さは必要だと考えます。
- 開発初期は、歩行できるポリシーを得るためにランダム要素をなるべく減らして最初は学習させていました。ランダム要素の1つとして、学習時に環境がリセットされたときのjointの初期角度をランダムにできるのですが、これを限定していました。PDゲインが低いことで起立後の各軸の角度が限定していた初期角度から大きくずれ、ポリシーへの入力が未学習の領域になり、不安定な動作を生んだことも一つの要因と考えました。
- 入力の遅延について。観測値を取得し目標角度を決定してから各モーターへ伝わるまでに遅れがある程度発生します。元々Isaac LabのDelayedPDActuatorを使用して実装し、5msから35msの間の遅れがランダム起こるように設定しておりました。これは学習する上では十分に確保できていると考えています。omni.isaac.lab.actuators ? Isaac Lab Documentation
- (時系列としては後から確認した数値ですが、) 中間層のサイズ[128, 64, 32]の3層MLPの計算時間を確認したところ一回約0.5msでした。ポリシーのNNはCPUで演算しており、振動していたときに使用していたのが[512, 256, 128]だったため(計算時間は約16倍の8msかかる)、ここが時間遅れを生んでいると考えて中間層を[128, 64, 32]に変更しました。
- 実際には、ネットワークサイズを落としても歩行性能は変わらなかったのを確認したので、わざわざ大きくする必要はないと判断しました。
まとめると、これらから以下のように変更しました。
- Action(ポリシーの出力)の平滑化報酬の重みを大きく
- 加速度の平滑化報酬の重みを大きく
- 各軸のPDゲインを大きく(河原塚先生が提供しているパラメータに戻す)
- 学習時の環境初期化時の各軸の初期角度のrandomize
- ポリシーとして使用していた3層MLPの中間層のサイズを[512, 256, 128]から[128, 64, 32]に小さく
この変更によって、滑らか、かつ、歩行周期が長くなるようなポリシーを作成したことで安定して歩行するようになりました。
初めて実機に適用したときの動画と、このときの歩行時のログがこちらになります。
自分たちで学習させた結果を使って歩けるようになりました!!#CoREjp#CoREjp_MAKING pic.twitter.com/CojMVCrNWe
? MA-KING (@ma_king_core) January 24, 2025
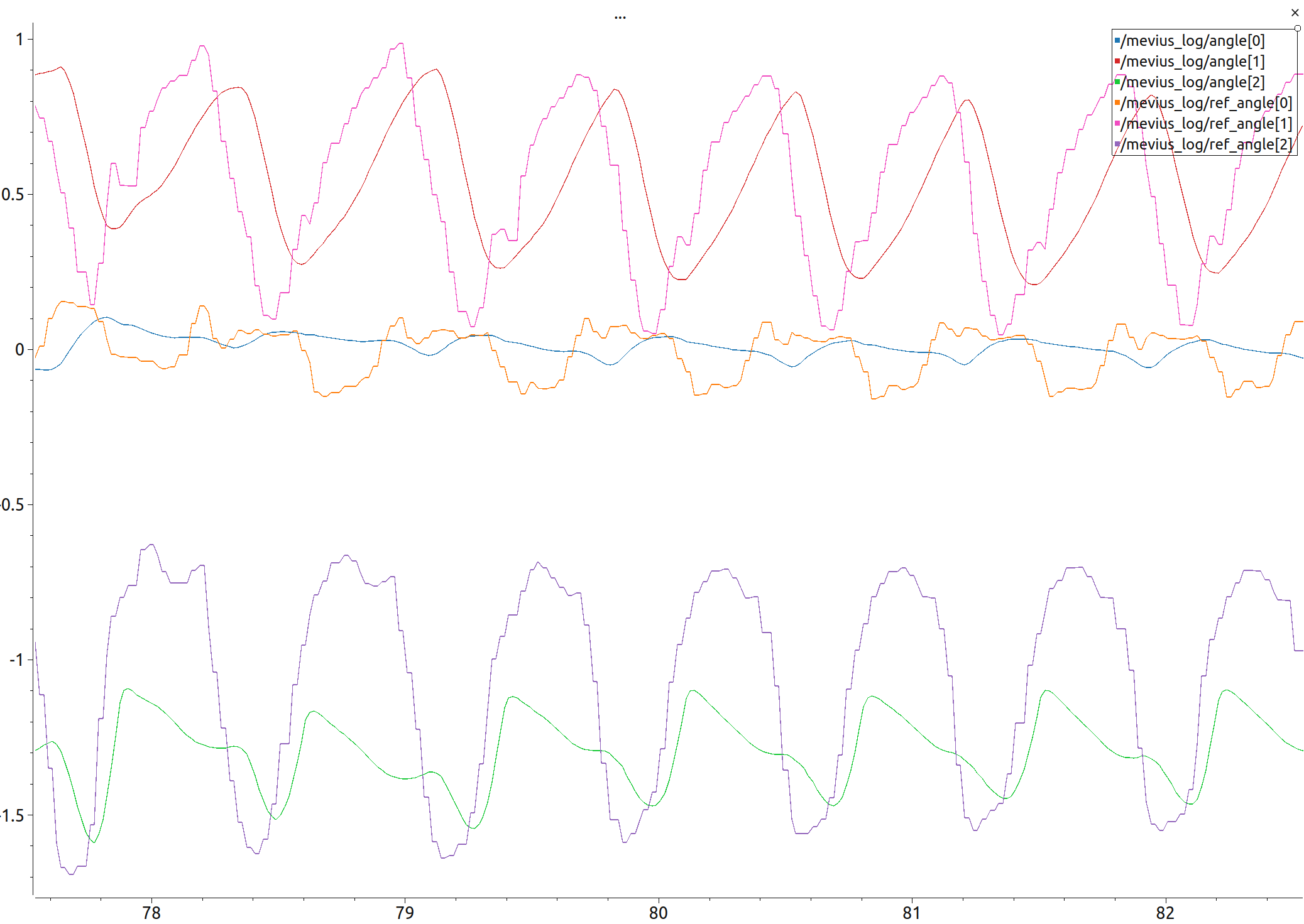 先程のグラフと比べて長い周期でロボットのアクション(各軸目標位置)が変化していることが確認できます。
先程のグラフと比べて長い周期でロボットのアクション(各軸目標位置)が変化していることが確認できます。
報酬の追加: すり足歩行などへの対応
この段階でのポリシーでは、特に速度の低いときや、旋回動作をするときにすり足になるような歩行になっています。カーペットのような摩擦の強い環境ではこのすり足による引っ掛かりの影響が大きくなります。実際のフィールドで用いられるロンリウムはこれほど摩擦の強い環境ではありませんが、より安定して歩行させるため、より好みの歩行が得られるような報酬を追加しました。
本日のMEVIUSです
その場旋回したり角速度入力もできそうです#CoREjp #CoREjp_MAKING pic.twitter.com/hTCkfOTRRz? MA-KING (@ma_king_core) January 26, 2025
Preferenceに相当する報酬として追加したものは以下になります。
- gait
- 対になる2脚がなるべく同期し、ペア間では逆位相になるような報酬(よりトロット歩行になるように誘導する報酬)
- foot slip
- 地面に接触している足のxy方向の速度にpenalty
- foot rhythm
- 各脚の浮遊期と立脚期の時間が指定した時間に近いほど高い報酬
- ait time valiance
- 各脚の浮遊期の長さになるべくバラつきがでないようにする報酬
追加の報酬導入後の歩行が動画のようになっており、通常歩行時に(特に低速でも)、足を上げることですり足が改善され、より安定感のある歩行になりました。(2/2実験)
また、すり足が改善されたことで、その場旋回の歩行についても安定感がかなり上がりました。
Heading Commandの追加
この時点で独自の報酬と重みを試しつつ、複雑環境で学習したポリシーを使用しているものの、段差はうまく越えられない、といったことが起こっていました。
段差越えに挑戦中です!#CoREjp#CoREjp_MAKING pic.twitter.com/MUU6rJz7BC
? MA-KING (@ma_king_core) February 2, 2025
そこで、Heading Commandを有効化して学習させたところ大きく歩行性能が向上しました。
このHeading Commandについて簡単に解説します。
ポリシーへの入力の一部にコマンドとして、
- x方向の速度
- y方向の速度
- 角速度
が存在します。学習中の「角速度」の指定には2パターン存在します。
- ランダムに指定した「角速度」を入力コマンドとして学習する
- ランダムに指定した「姿勢角(Yawのみ)」の目標値に対する角速度を入力とするP制御によるフィードバックで角速度を決定し、入力コマンドとして学習する(画像はイメージ: 目標のHeadingと機体のHeadingが重なるように角速度が生成される)
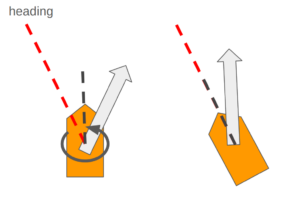
後者がHeading Commandを有効化して学習させるパターンになります。
前者を選択した場合、コマンドに関するランダムイベントによって目標角速度が変わるまで、常に指定された角速度でぐるぐる回り続けながら歩行しようとします。つまり、回りながらでも段差を越えられるポリシーを学習しようとするため、どうしても不整地走行に弱いポリシーが生成されます。
後者を選択すると、姿勢角が目標方向に向くまでは比較的大きな目標角速度が入力されますが、その後は、並進方向の目標速度のみが支配的になります。その結果、コマンドに関するランダムイベントが発生後、初期は並進+回転について学習し、後期は並進について学習するようになります。後期では、不整地の走破に集中してサンプルを収集できるため、高い不整地走破能力を獲得する方向に学習できます。
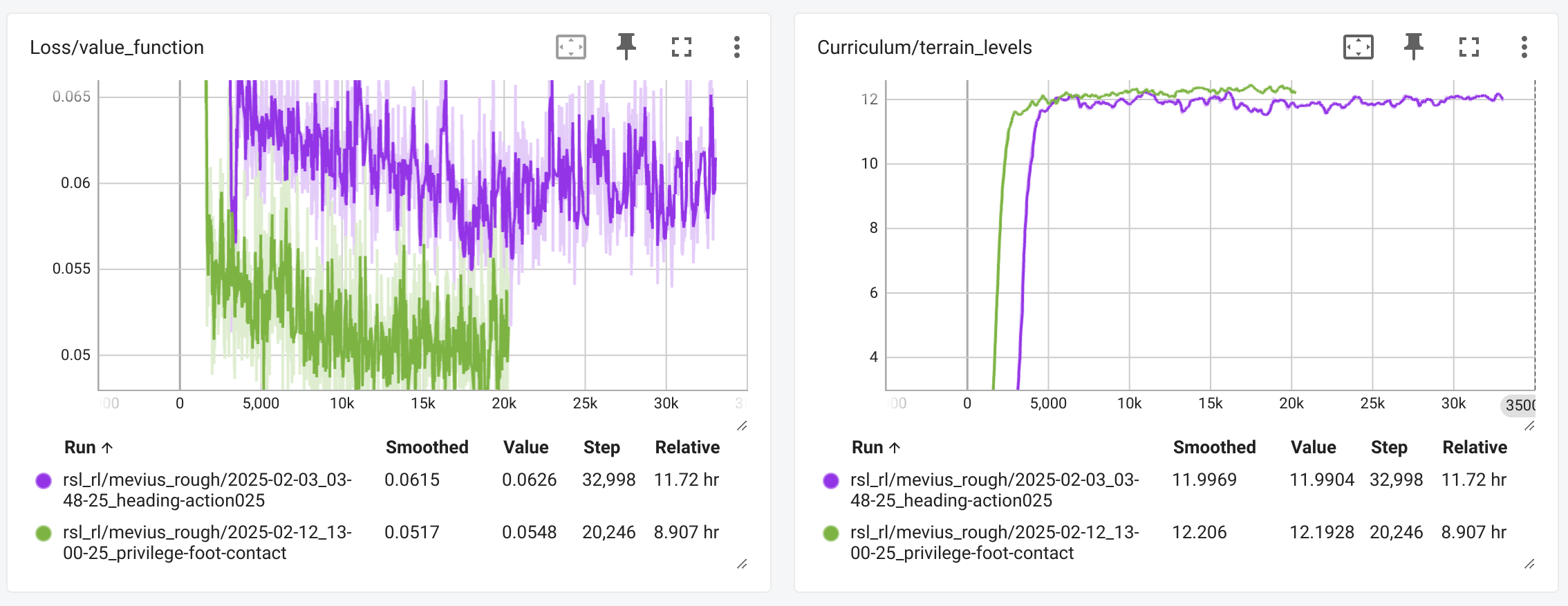
Heading Commandの有効化によって、より複雑な地形を走破できるようになりました。このときのterrain_levelsのグラフが下記になります。結果が出るまでは、ここまで効果のある要素だとは考えていなかったので驚きました。
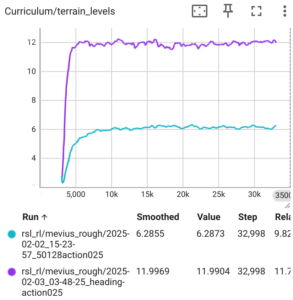
結果として、手法は異なるものの、こちらの論文(https://arxiv.org/abs/2010.11251)のFig.3aにあるものに近い、段差に対してひっかかった後に足の軌道修正する様子が観測でき興味深いです。
足が伸びた状態問題
こちらの動画にあるように、膝関節が可動域の制限に到達することで失敗することが何度かありました。後にハード側でもメカリミットでもって対応しましたが、制御側でも対応を行いました。
段差を越え…越え…#CoREjp#CoREjp_MAKING pic.twitter.com/85jMM0S6tv
? MA-KING (@ma_king_core) February 8, 2025
この時点では可動域の90%範囲を越えた場合に弱いpenalty報酬が加わるように学習させていましたが、75%範囲に対してより強いpenaltyを加えるように変更を行いました。
この変更前後における段差走行時の左右後脚の膝関節角度のログが下の画像になります。関節角制限をなるべく越えない歩容にすることができました。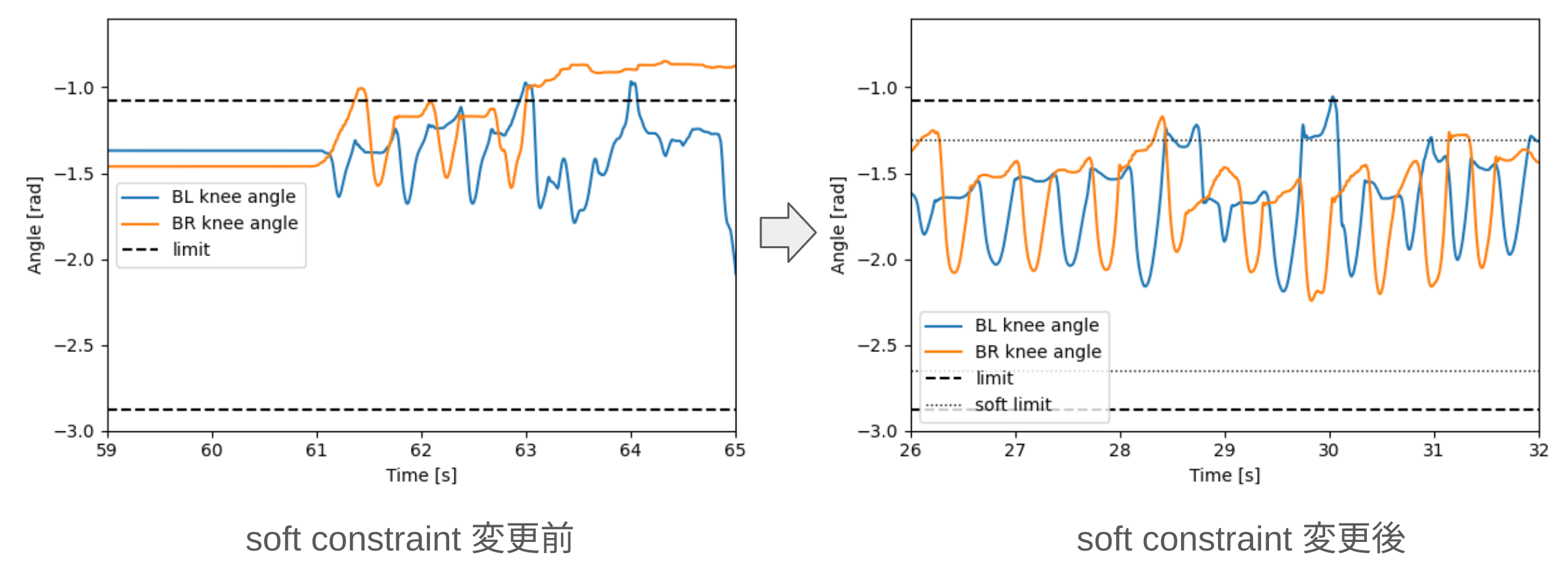 少しわかりにくいですが、修正後の歩容がこちらになります。
少しわかりにくいですが、修正後の歩容がこちらになります。
Asymmetric Actor Critic
下の動画にあるように、未だ失敗は多いため、次の解決策を追加で検討しました。
本日のNG集です#CoREjp#CoREjp_MAKING pic.twitter.com/3QnQcF6540
? MA-KING (@ma_king_core) February 15, 2025
歩行性能をより高めるため、強化学習のActor-Ciritic法におけるCriticにより多くの特権情報を追加するようにしました。
Actorは与えられた状態に対してどのように行動するべきかを決定する方策(ポリシー)を、Criticはある状態に対する累積報酬の期待値関数の近似、つまりその状態がどの程度良いのかを表現する状態価値関数を表します。
これまでは、Actor、Criticともに入力には以下を使用していました。
- 並進速度
- 角速度
- 重力方向
- 入力コマンド: xy方向速度, 角速度
- 関節角度
- 関節角速度
- Action (前回のポリシーの出力)
これに対して、Criticの入力に以下の特権情報を追加しました。
- 周辺地形の高さ
- 脚の接触力の大きさ
- 脚の接触力の方向
周辺地形の高さ情報としては、ロボット周辺の地形にRaycastした点を取ったものを使用しています。

これらの特権情報を追加することによって、複雑な地形との接触による報酬の変化をCriticで捉えることが期待できます。学習中に状態価値関数をより正確に近似できることによって、転倒などのリスクや潜在的な失敗を評価でき、より効率的かつ高い性能のポリシーが得られるようになります。
特権情報はCriticのみに追加することで、実機での推論時に必要な情報量には影響を及ぼさず性能を上げることが可能になります。
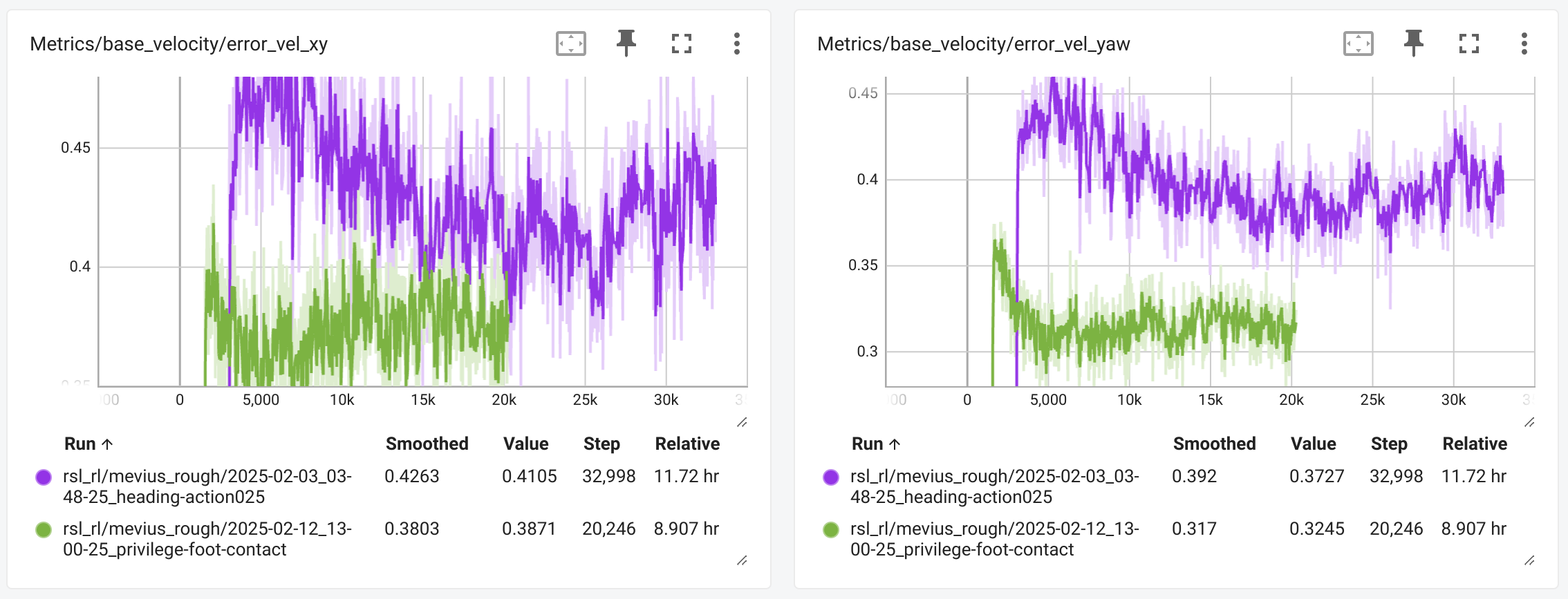
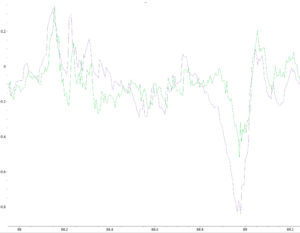
特権情報追加前後の学習時のログが以下になります。紫が追加前、緑が追加後になります。
価値関数の近似精度、走破可能なterrainレベル、速度コマンドに対する追従性も向上しています。
このポリシーにて実験したものが、こちらの動画になります。ここまで来て初めて連続する段差を超えることができるようになりました。
また、この特権情報追加後、なぜか内股寄りに歩行するようになりました。改良した結果、足の接地点間が小さくなるような歩行になるのか…と思ったものの、なんとなく実際の4足歩行動物を想起させる歩行なので、不思議かつ興味深いと感じます。(見当違いの可能性もあります)
(日付は先程のNGシーン投稿と同じですが、上記を事前に検討して用意していたものを試した結果です)
本番コースと同じ二連続の段差越えができました!!#CoREjp#CoREjp_MAKING pic.twitter.com/sNEtC1DQq1
? MA-KING (@ma_king_core) February 15, 2025
独自地形での学習
この時点で、段差走破の成功率は30~40%程でした。より安定した走破ができるポリシーを得るための工夫として学習する地形の変更を行いました。
2連続の段差によって、機体が上がって下がってを繰り返すことになるので、そのような環境でより多くのサンプルが集まるように画像のような地形を作成しました。
具体的な説明については、こちらの記事で行っておりますのでぜひご覧ください!
Isaac Lab Terrain(地形)設定 解説 ~CoRE用設定を添えて~ 4足歩行ロボット MEVIUS製作 Part.5
IMUの位置の変更
学習する地形の変更で成功率は約50%程でした。まだ安定はせず、失敗することが多いです。
ここで、ポリシーに使用している並進速度の観測座標系を間違えていることを思い出します。開発初期に一旦、並進速度の観測座標系が機体中心になるように学習させて、そのまま変更するのを忘れていた、という凡ミスです。IMUとしてはRealsense T265内蔵(Visual-Inertial Odometry計算後)の角速度、並進速度、姿勢情報を使用しているので、機体の頭についている計測値になります。
IMUの位置が異なると角速度、姿勢は同じであるものの、機体の並進速度は異なる値になります。開発初期では、段差のない環境での通常歩行を第一の目標としていたので、機体があまり傾くことなく並進速度もほぼほぼ同じだろう、という目論見で一旦実装を横着していました。
この横着をここで思い出し、なるべくIMUが学習時と正しい位置に来るように、Realsenseを頭の位置から機体中心位置に移動させて歩行させてみました。学習時と同じ観測データになるように調整するという至極当然のことではありますが、結局この改善が一番段差超えの安定性が上がる要因になりました。これまでの改善が相乗効果で乗っているからだと信じていますが…。この時点で、成功率はほぼ100%だったと思います。
みなさんが抱くであろう疑問:
- 正しいIMU位置で学習させれば良いのでは?
- 試しました。しかし、あまり性能が良くなかったです。こちらは大会直前での実装だったので深く原因究明はできていないです。
- 安定感はIMUを機体中心に配置したときのほうが遥かに高かったです。特に動画(後参照)のように後退するときの歩行性能はかなり下がりました。
- 座標変換すれば良いのでは?
- 試しましたがあまりよくなかったです。計算間違いしていたので(照) (機体座標系から見た並進速度ではなくGlobal座標系から見た並進速度を計算していました)
- 修正して検証したものを後ほど紹介します
その結果、安定感がかなり上がり、動画のように段差の経路の往復などをさせても危なげなく歩くことができるようになりました。
安定して段差もクリアできるようになってきました!#CoREjp#CoREjp_MAKING pic.twitter.com/en94GCgvSF
? MA-KING (@ma_king_core) March 20, 2025
並進速度の座標変換
大会後にはなりますが、IMU (Realsense T265)を頭につけて、学習に使用した座標系での正しい並進速度となるように変換計算をして実験を行いました。
変更前がこちらになります。特に動画00:08~ あたりで頭を中心にしてその場旋回をしようとしていることが確認できるかと思います。これがIMU位置が異なることによる、わかりやすい一つの影響ですね。
変更後がこちらになります。頭にIMUを設置していますが、体の中心を回転中心としてその場旋回できるようになっていることが確認できるかと思います。(動画00:58~)
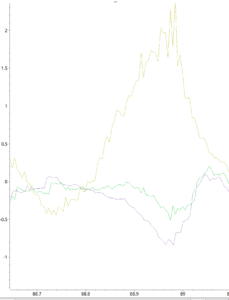
こちらは、動画00:36~00:38の段差通過時の並進速度のz成分をプロットしたもの(緑が補正前、紫が補正後)になります。グラフ2つ目は、このときの機体のy軸周辺の角速度(黄色)も同時にプロットしたものになります。機体の座標系は、進行方向をx軸正、鉛直方向をz軸正として取っているので、y軸周辺の角速度が機体の姿勢が上下することで大きく変化します。
グラフ1枚目で負に大きく変化している部分が段差から降りる瞬間のデータになります。IMUが頭についていることで紫のグラフのように機体のz方向の速度が大きく負方向に変化しています。しかし、角速度情報によって機体中心の並進速度に補正され、緑のグラフに示されるように速度変化が抑えられていることが確認できており、正しく補正計算ができていそうです。このような大きな角速度が入ったときの観測値の精度が、転倒に対するロバスト性を左右するというのは感覚的に納得感があるかと思います。
変換をしても高い走破率を維持することができており、IMUを頭につけることでVisual-Inertial Odometryのための視界を多く取ることができ、より安定してIMU情報を活用できるかと思います。
感想
楽しかったです。とても。新しいことに手を出すのはワクワクして良いですね。
各フェイズで原因を考えるときに、必ず”報酬のパラメータの配分が悪いからか…?”という考えになります。このフィードバックに数時間かかるので苦しかったですね。その分いろいろ経験してみないとわからないノウハウは得られたつもりです。
実験の際には、基本的にはいくつかのパターンを事前に学習させて持っていき、軽微な修正点があれば別のポリシーを実験している間に修正して追加学習、のサイクルで練習を行っていました。
ただ、いざ実験するぞ!ってなったときに一個目のポリシーが根本的にダメだとわかり、それが全てのポリシーに共通する場合、微調整では済まず初めから学習させなおす必要があるので、最速でも実験できるの8時間後!となり絶望することがありました(笑)
強化学習ベースの制御の魅力としては、学習環境を一度整備してしまえば、後は報酬や設定の追加・変更などで異なるポリシーを生成することができるので、モデルベースのように新機能を構造の中に新規実装することがなく、ゴール(目標の挙動)を報酬などを通じて、比較的簡単に設計することができる点かなと思います。
逆にいうと、出力を決定するまでの情報の流れが存在しないので、入力と出力の妥当性しか判断材料がなく、得られた行動に対してデバッグをするのが難しい、という側面もあります。モデルベースでも構造が複雑化した場合、情報は追えるものの特定が難しいこともしばしばありますが、状態推定結果の妥当性などの検証はできるため、比較的問題把握はしやすいという認識です。
また、強化学習ベースで制御器を設計する際、報酬という形で設計項目が独立していて、学習曲線からどの要素が大きく影響を及ぼしているかを確認することができるため、作りやすかったという印象です。ただし、想定通りの結果が得られるように、学習できるようにする・パラメータを見つけるのは職人芸の一面があるのでご注意ください。
まとめ
以上が、MA-KINGでMEVIUSによる強化学習ベースの制御器を開発した際の一連の改善の流れと開発者の思考になります。失敗から推定した根拠に対し、取った変更によって狙った部分が改善されていることは確認していますが、冒頭に申し上げたとおり、根拠部分の妥当性に関しては一部間違いを含んでいる可能性がありますので今一度ご注意ください。
昨今注目を浴びる強化学習ベースのロコモーション制御に関するtry and errorの記録はなかなか公開されている情報ではないと思いますので、この内容が読んだ方のお役に立てば幸いです。