

ChatGPTと連携させよう
ChatGPTと連携させ、会話ができる「おしゃべりスタックチャン with ChatGPT」を作ります。
動作させる流れはスタックチャンリポジトリのドキュメントに書かれています。基本的にはこの手順に従えば大丈夫です。
実際には以下のような流れになります。
- スタックチャンに話しかける
- 近くに設置したPCで音声の受信、文字に起こしてスタックチャンに渡す
- スタックチャンがChatGPTと通信して返答内容の文章を得る
- PCと通信して音声データに変換してスタックチャンに渡す
- スタックチャンに喋ってもらう

ChatGPTと連携して喋るスタックチャンのシステム構成
動作時のイメージは以下の動画の通りです。
音声認識サーバーの準備
環境の準備
音声認識としてオープンソースのVOSKを使用します。ここでは、ししかわさんが公開しているシェルを使って簡易のWebSocketサーバーの環境を整えます。
リポジトリをcloneした後にnpm installを行い必要なパッケージをインストールします。
$ git clone https://github.com/meganetaaan/simple-stt-server.git
$ cd simple-stt-server
$ npm install
VOSKのモデルファイルの準備
次に、任意のVOSKのモデルファイルをダウンロードして展開します。今回は日本語で会話するので、容量1GbのモデルBig model for Japaneseを使用します。

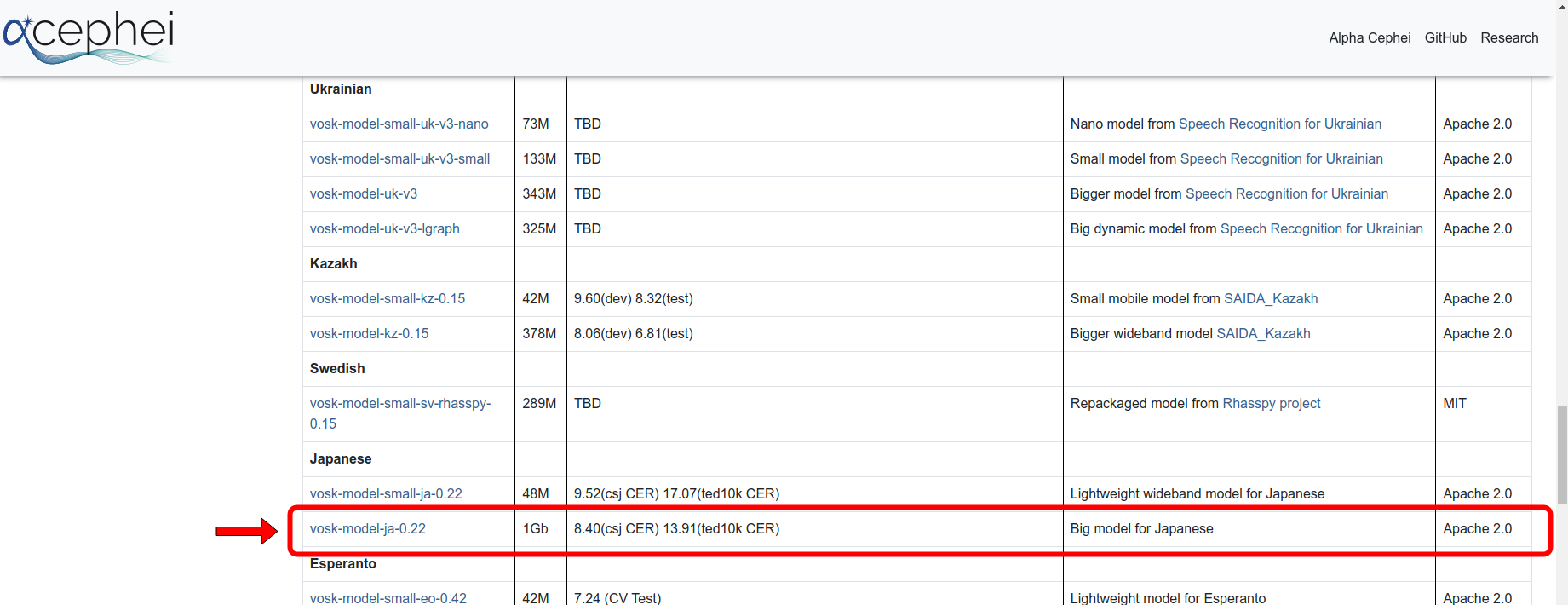
simple-stt-serverのディレクトリの配下にmodelディレクトリを作成し、展開したモデルファイルを中に入れたら準備は完了です。
起動
npm startコマンドで起動させて文字起こしが出来ますが、私の使用したPCマイクの認識が出来ませんでした。そこで、引数として-- --device defaultを与えることでPCのマイクが認識することができ、実行できました。
$ npm start -- --device default
> suburi-vosk@0.0.1 start
> node index.js --device default
LOG (VoskAPI:ReadDataFiles():model.cc:213) Decoding params beam=13 max-active=7000 lattice-beam=6
LOG (VoskAPI:ReadDataFiles():model.cc:216) Silence phones 1:2:3:4:5:6:7:8:9:10
LOG (VoskAPI:RemoveOrphanNodes():nnet-nnet.cc:948) Removed 1 orphan nodes.
LOG (VoskAPI:RemoveOrphanComponents():nnet-nnet.cc:847) Removing 2 orphan components.
LOG (VoskAPI:Collapse():nnet-utils.cc:1488) Added 1 components, removed 2
LOG (VoskAPI:ReadDataFiles():model.cc:248) Loading i-vector extractor from model/ivector/final.ie
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:183) Computing derived variables for iVector extractor
LOG (VoskAPI:ComputeDerivedVars():ivector-extractor.cc:204) Done.
LOG (VoskAPI:ReadDataFiles():model.cc:279) Loading HCLG from model/graph/HCLG.fst
LOG (VoskAPI:ReadDataFiles():model.cc:294) Loading words from model/graph/words.txt
LOG (VoskAPI:ReadDataFiles():model.cc:303) Loading winfo model/graph/phones/word_boundary.int
LOG (VoskAPI:ReadDataFiles():model.cc:310) Loading subtract G.fst model from model/rescore/G.fst
LOG (VoskAPI:ReadDataFiles():model.cc:312) Loading CARPA model from model/rescore/G.carpa
listening on port 8080
Received Info: 録音中 WAVE 'stdin' : Signed 16 bit Little Endian, レート 16000 Hz, モノラル
{ text: '' }
{ text: '' }と表示されていれば起動しています。マイクに向かってしゃべると文字起こしがされます。
ためしに、『テスト』と言ってみると…
{ text: '' }
{ text: 'ん テスト' }
message sent: {"role":"user","message":"ん テスト"}
無事『テスト』と出力されました!(『テスト』と発生するまえに『ん』がはいってしまってますが)
これでスタックチャンに話しかける機構ができあがりました。この文字をChatGPTに送り、返答の文章をスタックチャンに喋ってもらいます。
音声合成サーバーの準備
環境の準備
ChatGPTからの返答の文章をスタックチャンの発話に変換する必要があります。それには音声合成サーバーのvoicevox_engineを使用します。
早速プログラムをclone(ダウンロード)して環境を構築します。
git clone https://github.com/VOICEVOX/voicevox_engine.git起動
voicevox_engineの環境構築では、Dockerを使用する方法が簡単なのでおすすめです。Dockerは、コンテナと呼ばれる任意の構成の仮想環境を簡単に用意できるツールです。
Docker
voicevox_engineを使用するためにはいくつかのソフトウェアパッケージをインストールしておく必要がありますが、それらを既に備えたコンテナを構築する情報(Dockerイメージ)を開発側が用意してくれています。このDockerイメージを利用すれば、voicevox_engineを簡単なコマンドで起動できます。
Dockerのインストール手順は、以下の公式ページで解説されています。

Dockerを使用して起動
Dockerを利用する方法では、以下の2つのコマンドですぐに動作が開始します。前章で起動させた音声認識サーバーは閉じず、新たなシェルを開いて実行します。
$ docker pull voicevox/voicevox_engine:cpu-ubuntu20.04-latest
$ docker run --rm -p 50021:50021 voicevox/voicevox_engine:cpu-ubuntu20.04-latest
+ cat /opt/voicevox_engine/README.md
# VOICEVOX エンジン利用規約
## 許諾内容
1. 商用・非商用問わず利用することができます
2. アプリケーションに組み込んで再配布することができます
3. 作成された音声を利用する際は、各音声ライブラリ
(中略)
+ exec gosu user /opt/python/bin/python3 ./run.py --voicelib_dir /opt/voicevox_core/ --runtime_dir /opt/onnxruntime/lib --host 0.0.0.0
Warning: cpu_num_threads is set to 0. Setting it to half of the logical cores.
reading /home/user/.local/share/voicevox-engine-dev/user.dict_csv-8af91a69-75ac-4735-9237-fb83122277f8.tmp ... 75
emitting double-array: 100% |###########################################|
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:50021 (Press CTRL+C to quit)
GPUを搭載したマシンではGPUを使うことでレスポンスが早くなります。 GPUに対応したVOICEVOX Dockerイメージを起動するには以下のコマンドになります。$ docker pull voicevox/voicevox_engine:gpu-ubuntu20.04-latest$ docker run --rm -p 50021:50021 voicevox/voicevox_engine:gpu-ubuntu20.04-latest
スタックチャンの準備
ホストの書き込み
プログラム内の設定を変更する
manifest_local.json (stack-chan/firmware/stackchan/manifest_local.json) のconfigに必要な設定を追加・変更します。
- ai.token: ChatGPTのトークン(取得したChatGPTのトークン)
- tts.host: IPアドレス(ネットワークから自分のPCに割り当てられたIPアドレス)
{
"include": [
"./manifest.json"
],
"config": {
"ai": {
"token": "ChatGPTのトークン"
},
"tts": {
"type": "voicevox",
"host": "IPアドレス",
"port": 50021
}
}
}
SSIDとPASSWORDの設定付きでビルドして書き込む
スタックチャンを接続するWi-Fiルータのssidとpassewordをコマンドに入力しビルドします。その後 deployで書き込みをします。
$ npm run build --target=esp32/m5stack_cores3 ssid="Wi-FiのSSID" password="Wi-Fiのパスワード"
$ npm run deploy --target=esp32/m5stack_cores3
Modの書き込み
スタックチャンのソフトウェアで使用しているModdableには、Modという仕組みがあります。スタックチャンのベースとなるプログラムのHostに対して機能を追加して動作させるもので、ユーザーは基本的にModによって独自の機能を組み込みます。
スタックチャンとModdableの仕組みは過去のブログで紹介しています。

ChatGPTのモデルを変更する
stack-chan/firmware/mods/chatgpt/mod.jsで定義されているスタックチャンに使用するChatGPTのモデルを、2024年6月7日現在で最新のgpt-40に変更します。
const STT_HOST = 'stackchan-base.local' // const MODEL = 'gpt-4' // const MODEL = 'gpt-3.5-turbo' const MODEL = 'gpt-4o'
Modを指定して書き込む
ChatGPTを動かすModを書き込んだら準備完了です!
$ npm run mod --target=esp32/m5stack_cores3 mods/chatgpt/manifest.json
スタックチャンとお喋り
音声認識サーバーと音声合成サーバーを予め立ち上げた状態でスタックチャンを起動してください。
実際に会話してみた
PCのマイクに向かって話しかけるとスタックチャンが返答してくれます。
お話できました!!
動画の通り、スタックチャンとの会話で無事お散歩に連れ出すことに成功しました。私はスタックチャンとお出かけしてくるのでここら辺で失礼します。
あとは皆さんのスタックチャンを喋らせてあげてください!
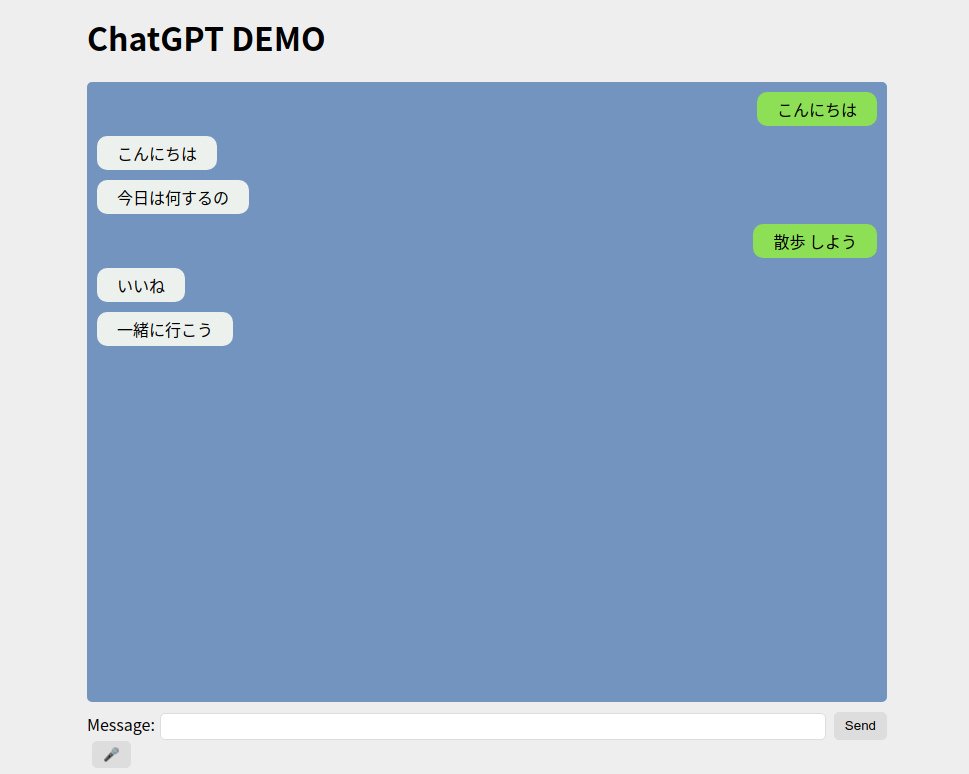
ブラウザからも会話
音声認識サーバーを立ち上げたPCのアドレス:8080にアクセスするとチャット風画面が立ち上がります。
認識したメッセージと、スタックチャンの返答が確認できます。また、Messasgeに文字を入力してSendボタンでスタックチャンに送信することも出来ます。
『スタックチャン アールティver.』好評発売中!
『スタックチャン アールティver.』は絶賛好評発売中です。是非購入してスタックチャンとお喋りしてみてください!
スタックチャン アールティver. 組立キット

スタックチャン アールティver. (完成品版)

