

前回の記事では、ALOHA(A Low-cost Open-source Hardware System for Bimanual Teleoperation)の片側のリーダーロボットとフォロワーロボットを製作し、遠隔操作で唐揚げのピッキングを行いました。本記事では、両側のリーダーフォロワーロボットとカメラを含む完全なALOHAで、模倣学習でクリスマスの飾りつけ動作を獲得させます。
クリスマスの飾りつけタスク
本記事で扱う飾りつけタスクは、2024年のクリスマス(Happy Holidays)を祝うホリデー動画の作成のために設定されました。最初に、机の上にある小さな飾りを両側のロボットでそれぞれ持ち上げ、ツリーの枝葉を模した板の上に置きます。次に、机の上にあるモールを両側のロボットで持ち上げ、Muriquiの首に掛けます。タスクの成功例は、ホリデー動画として公開しています。
動作生成モデル
ALOHAの動作生成には、ALOHAの論文で使用されたAction Chunking with Transformers(ACT)というTransformerアーキテクチャに基づくモデルを使用します。このモデルは、条件付き変分オートエンコーダとTransformerアーキテクチャを組み合わせたもので、ロボットの関節角度とカメラの画像をラベルとして動作を生成します。
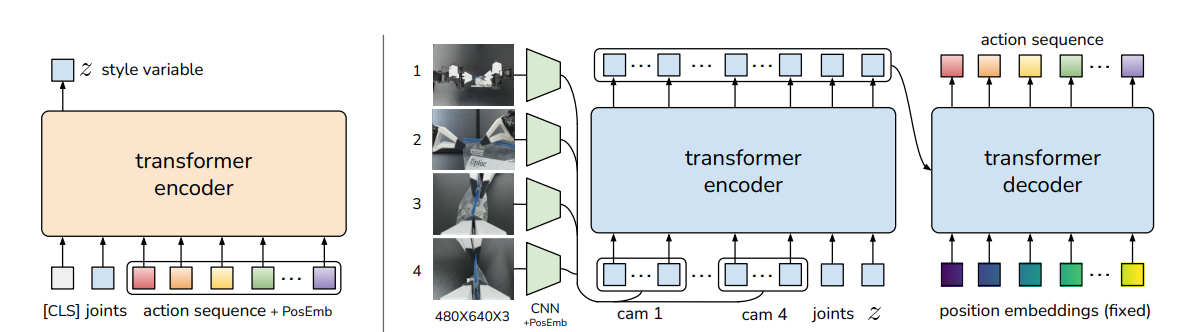
Architecture of Action Chunking with Transformers (ACT), Tony Z. Zhao, et. al., Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
モデルの学習と検証
モデルの学習と検証には、人が遠隔操作して得られた51回の教示データを使用しました。教示データには、20msの間隔で30秒間取得したALOHAの関節角度と4つのカメラ画像(フレーム上部と下部、左右のフォロワーロボットの手先)が含まれていました。ツリーの飾り・モール・ツリー・Muriquiの初期位置を固定して教示データを収集しました。
51回の教示データのうち80%を学習用データとし、残りを検証用データとしました。エポック数を3000に設定し、RTX A6000を搭載したPCで学習したところ、学習時間は約3時間かかりました。学習を行ったときのL1ロスのグラフを以下に示します。
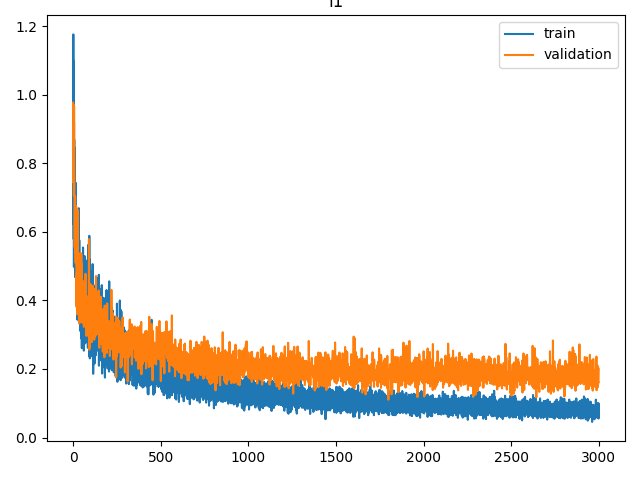
Validationの値が最小のときのパラメータを使用してACTモデルを動作させると、ALOHAが目的の飾りつけを行うように動作しました。ただし、動作生成にはRTX4060を搭載したPCを使用したため、計算が追い付かず動作速度は教示時と比べて1/2程度になりました。
失敗例
学習データには物体の初期位置が固定された状態での教示データしか含まれていないため、この学習データを使用して学習したモデルは、飾りの位置の変化に対応することができません。以下の動画では、同じパラメータを使用して失敗したときの様子を示しています。
飾りの位置を変えたときの教示を含めて学習データを増やすと、飾りの位置の変化に対応するようにモデルを学習させることができると考えられます。
その他のタスクとモデル
ブロック積みなどの他のタスクを学習させた場合では、ブロックを掴み損ねたときに再度ブロックを掴もうとする動作が生成されることを確認しました。
また、デコーダーだけを使用するように改良されたモデルHumanoid Imitation Transformerを使用することで、性能が向上すると考えられます。
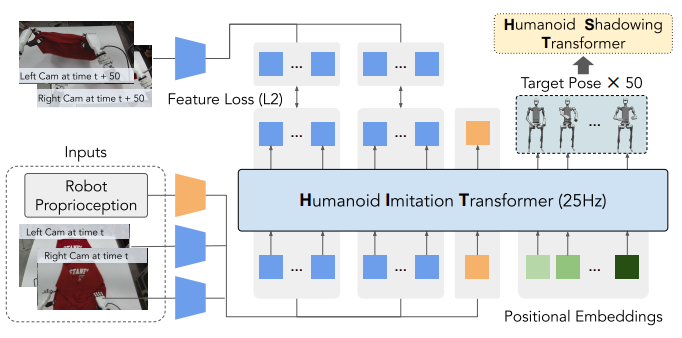
Model Architecture of Humanoid Imitation Transformer, Zipeng Fu, et. al., HumanPlus: Humanoid Shadowing and Imitation from Humans
模倣学習キット「RT-IM2024」の販売が決定!
ところで、本記事で使用したALOHA(A Low-cost Open-source Hardware System for Bimanual Teleoperation)を模したロボットは、模倣学習キット「RT-IM2024」として受注生産で販売されることが決まりました。本記事で紹介したように、遠隔操作による模倣学習を行うことができます。ALOHAの論文で使用された学習スクリプトが変更なしで動作するので、再試に最適です。ぜひお買い求めください。

